The Duplicate You Tolerate Is a Decision You’ve Made
What happens when the ambiguity you've been tolerating meets something that acts at machine speed

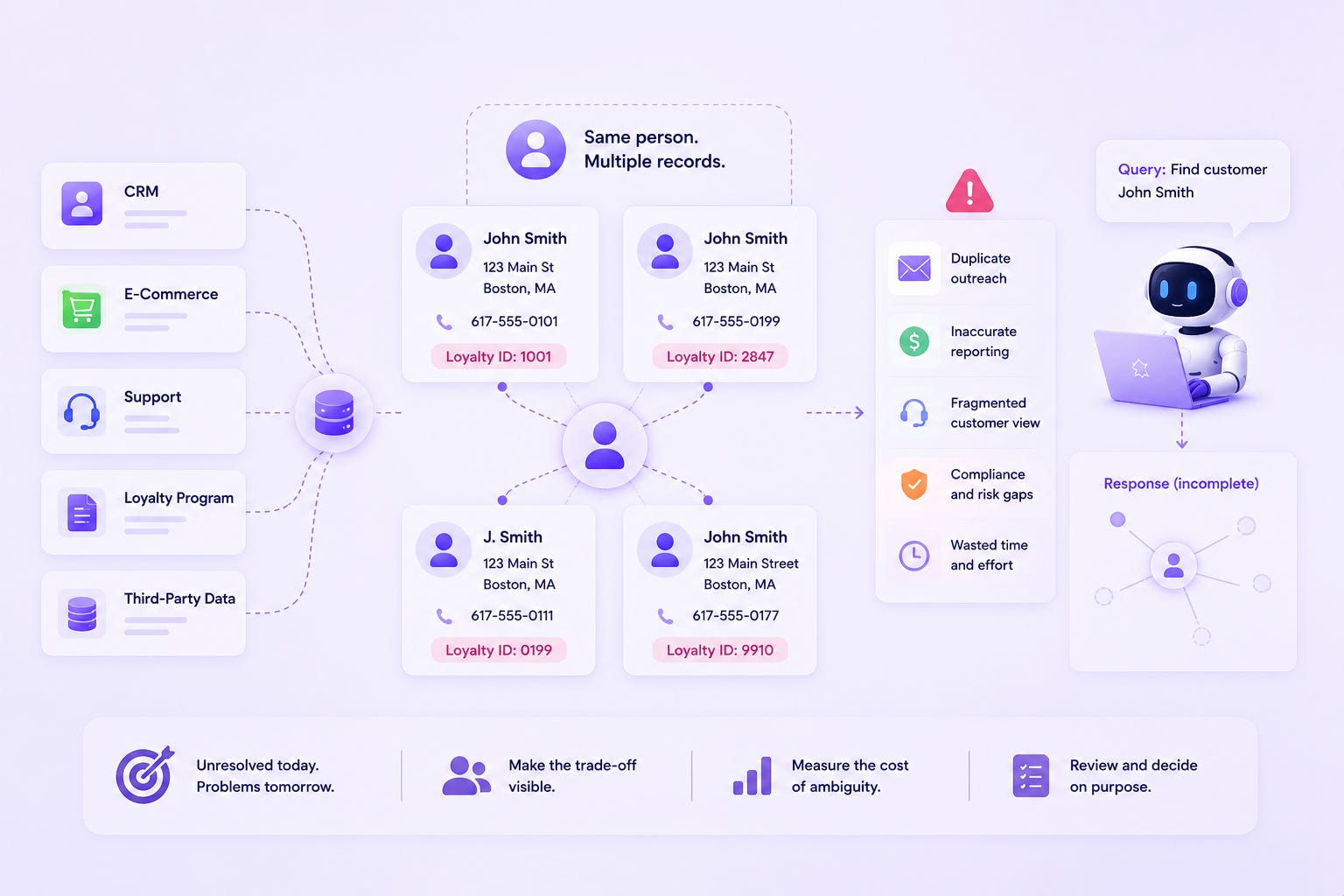
A few months ago, I sat in on a data quality review at a retail company I was working with. Someone pulled up the customer master and pointed to a pair of records — same name, same address, different phone number, different loyalty ID. “We know about these,” she said. “We’ve known for two years. They’re on the list.”
I asked what list. Turns out there’s a spreadsheet. Six thousand rows of duplicate pairs, flagged, reviewed, and never merged. Not because anyone decided they shouldn’t be merged — because nobody ever decided anything. The list just grew.
That spreadsheet is not a data quality gap. It’s a policy. Nobody wrote it down, nobody approved it, but the organization has effectively decided: these six thousand records get to stay ambiguous. That decision has been made by inertia, not by anyone with the authority to make it — which is exactly what makes it dangerous.
Every “we’ll get to it” is a choice with a cost
I think we talk about duplicate records the wrong way. We treat them like a bug — an embarrassing mess that a big enough data cleanup project will eventually fix. That framing lets everyone off the hook. Bugs are nobody’s fault. Policies are somebody’s decision.
Here’s what I mean by that shift. When a data team says “we’ll get to those duplicates next quarter,” they’re not describing a technical backlog. They’re making a resourcing decision that has a direct downstream cost, and that cost is being paid by someone else — the sales rep who calls a customer twice, the finance team that can’t tell if two invoices are for the same vendor, the support agent who can’t see a customer’s full history because it’s split across two records.
In Financial Services, I’ve seen this show up as unresolved entities across onboarding and servicing systems — the same client, one profile for account opening, one for wealth management, never joined. The bank isn’t unaware. Someone made a call, at some point, that reconciling those two systems wasn’t worth the engineering quarter it would take. That’s a reasonable call to make. What’s not reasonable is not admitting a call was made at all.
In Healthcare, the stakes get sharper. A patient with two MRNs because their name was misspelled at intake five years ago isn’t a data quality footnote — it’s a medication history that doesn’t fully surface, a risk flag that doesn’t propagate, a care team working from half the picture. Someone, somewhere, decided that the identity resolution backlog wasn’t urgent enough to prioritize. Every day that decision stands unreviewed, it’s being made again by default.
The math nobody does
The reason duplicate tolerance persists as an invisible policy is that nobody actually prices it. Merging two records has an obvious, bounded cost — you can put a number of engineering hours or a subscription fee against it. Not merging them has a cost too, but it’s diffuse: fifteen minutes here from a sales rep working a stale lead, a compliance review that takes an extra day because two versions of the same vendor won’t reconcile, a customer who gets marketing emails twice and unsubscribes from both.
Diffuse costs lose budget conversations to bounded costs, every time. That’s not a data problem. That’s an incentive problem. The team that owns the “let’s not deal with it yet” decision is rarely the team that absorbs the daily cost of tolerance. So the backlog grows, and it keeps growing precisely because it’s working exactly as designed for the people deciding not to act.
Why this gets worse, not better, with agents
Up to now, the cost of a tolerated duplicate has mostly been friction. A human eventually notices something’s off — a rep double-checks before a call, a support agent asks a clarifying question, an analyst catches an oddity in a report and shrugs it off. Humans are pretty good at absorbing ambiguity without acting badly on it.
Agents are not. An agent that queries the customer master doesn’t pause to wonder if there might be a second record. It acts on what it’s given, with full confidence, at whatever speed you’ve built it to run at. The duplicate you’ve tolerated for two years because “it’s on the list” becomes the duplicate an agent updates only one half of, emails only one version of, or bases a decision on without ever knowing the other version exists.
This is the part I keep coming back to with the teams I talk to: tolerating ambiguity was a survivable policy when humans were the ones acting on the data. It stops being survivable the moment something acts on your data at machine speed and machine scale. The backlog doesn’t just sit there anymore, quietly costing you friction. It becomes the thing your automation trips over, repeatedly, invisibly, until someone downstream notices the pattern of small wrong actions and traces it back to a spreadsheet nobody owns.
Naming the policy is the first step
I don’t think the fix here is “resolve every duplicate immediately” — that’s not realistic, and honestly it’s not even always the right call. Some ambiguity is genuinely low-stakes and fine to leave alone. The fix is smaller and more honest than that: name the policy out loud.
If your organization is tolerating a backlog of unresolved entities, someone with the authority to make that trade-off should be the one making it — on purpose, with a rough sense of what it’s costing, and with a plan for revisiting it as the stakes change. Not a spreadsheet that grows by accident because reconciling it was never anyone’s job.
That’s a people-and-process conversation before it’s a technology one. But the technology conversation matters too, because part of why duplicates pile up invisibly is that most matching systems give you a one-time cleanse and then go quiet — no continuous resolution, no visibility into what’s drifting back into ambiguity, no feedback loop that lets a human steward correct the model’s judgment as new records come in. A backlog that regenerates itself is much easier to tolerate by accident than one you have to actively watch grow.
So here’s my question for you: what’s the “list” in your organization — the backlog everyone knows about, nobody owns, and nobody’s priced? And if an agent started acting on it tomorrow, would you still be comfortable with the decision you didn’t know you’d made?
If you're building toward a future where agents act on your customer data, this is the newsletter for the questions that come before that — like this one. Subscribe, and let me know what your "list" looks like.