The Data Team’s Moment: How Agentic AI Is Turning the “Support Function” Into the Strategic Center of the Enterprise
For years, data teams were the quiet backbone nobody appreciated. That is changing — fast.

There’s a meeting that happens in every organization, usually sometime in Q3 or Q4. A CFO pulls up the budget spreadsheet, squints at the line items, and asks the question that makes every data leader’s stomach drop: “What exactly are we getting out of the data team?”
It’s an uncomfortable question — and for a long time, it didn’t have a clean answer.
Data teams built pipelines nobody asked about, maintained dashboards that were exported to Excel before anyone actually read them, and spent political capital defending headcount to executives who viewed them as a sophisticated cost center. As Joe Reis, author of Fundamentals of Data Engineering, put it plainly: “Data teams will continue struggling to justify their value as long as data in Enterpriseland is a back-office function.”
That was the reality for most of the 2010s and into the early 2020s. Data teams worked in the shadows — vital infrastructure, but rarely celebrated. They were the plumbers of the modern enterprise: essential when things worked, blamed when things didn’t, and invisible the rest of the time.
The era of agentic AI is changing all of that — right now, in real time.
The Old Indignity: Fighting for a Seat at the Table
The data ROI conversation has long been a recurring humiliation dressed up as a business exercise.
Unlike sales, whose numbers are on the board every Monday morning, or marketing, which can point to impressions and conversions, data teams have operated in the murky middle. Their impact is indirect — they help other teams make decisions. As data writer Anna Geller captured it well: “Most data teams work as a support function... their involvement in value creation is indirect. You can’t directly quantify the impact of a new table, dashboard, or pipeline.”
This indirectness has been weaponized against them at budget time. Data leaders find themselves in a paradoxical position: the team responsible for quantification can’t quantify itself. Some resort to building internal P&L reports to justify their own existence. Others try charging other departments “internal fees” for data services — a workaround that says more about the dysfunction of how data is valued than it does about the team’s actual contribution.
Meanwhile, data stacks keep growing enormous. As Monte Carlo’s blog noted, “data teams made history as one of the first departments to spin up 8-figure technology stacks with little to no questions asked” — a fact that makes them conspicuous targets whenever CFOs start scrutinizing every line item with new intensity.
The modern data stack is a marvel of engineering. But without a clear, legible link to revenue, it remains a liability in any budget conversation. At least, it has been — until now.
The Shift Underway: AI Agents Are Looking for a Nervous System
Here’s the thing about agentic AI: it is only as good as the data it runs on.
This seems obvious, but its implications are still rippling through the enterprise in real time. When a company deploys an AI agent to autonomously manage customer service tickets, optimize supply chains, approve procurement requests, or run financial reconciliations, every decision that agent makes is being built on a data foundation. If that foundation is shaky — inconsistent definitions, poor lineage, unresolved duplication — the agent doesn’t just underperform. It fails loudly, in production, with consequences.
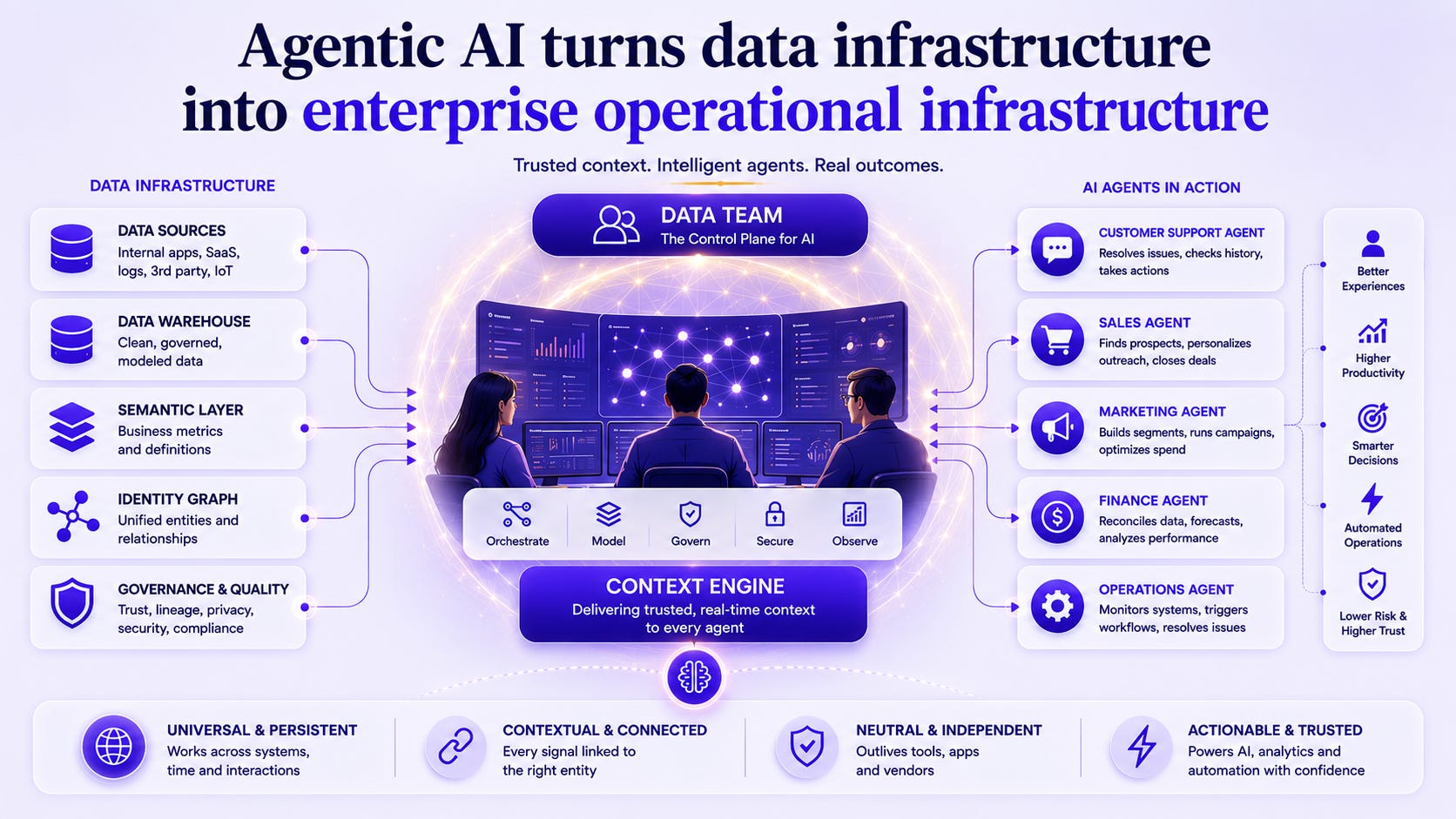
Robin Sutara, Field CDO at Databricks, is making this organizational implication explicit in Databricks’ 2025 strategic priorities report: “A successful AI strategy starts with a solid infrastructure. Addressing fundamental components like data unification and governance through one underlying system lets organizations focus their attention on getting use cases into the real-world, where they can actually drive value for the business.”
The work that data teams have been doing for years — data quality, entity resolution, governance, lineage, pipeline reliability — is no longer background noise. It is becoming the prerequisite for the most important initiative in every company.
The budget conversation is flipping. It’s no longer “justify why we need you.” It’s “how fast can you get us AI-ready?”
The Numbers Bearing This Out
The scale of the agentic AI wave is making clear why data teams are starting to matter in a way they simply haven’t before.
Gartner predicts that 40% of enterprise applications will be integrated with task-specific AI agents by the end of 2026 — up from less than 5% today. By 2028, at least 15% of work decisions across organizations will be made autonomously by AI agents, up from virtually zero in 2024. And Gartner’s best-case projection suggests agentic AI could drive approximately 30% of enterprise application software revenue by 2035, surpassing $450 billion.
The old framing — tools automate tasks, people make decisions — is no longer holding. And the people who build, govern, and maintain the data powering this new paradigm are moving from the back office to the top of the boardroom agenda.
The Verizon Test Case
Few leaders are articulating this shift as clearly as Kalyani Sekar, Verizon’s Chief Data Officer. In a 2025 interview with CDO Magazine, she describes the arc of her team’s work — and its growing centrality — with unusual candor:
“Data quality is foundational to Verizon’s long-term goals. As we continue to roll out more analytical use cases, from predictive and prescriptive to generative and agentic, it’s critical that these AI and analytical capabilities, including the reports built on them, are grounded in data that is trustworthy and of the highest quality.”
Verizon handles petabytes of data daily — from network devices, customer touchpoints, service channels. The data team’s job was always to make sense of it and surface insights. Today, that same infrastructure is becoming the operating layer for autonomous AI systems making real-time decisions affecting 140 million wireless retail connections.
The data team isn’t changing. The stakes around its work are.
From Cost Center to Control Plane
McKinsey’s 2025 research on the “agentic organization” is describing what’s unfolding as the largest organizational paradigm shift since the industrial revolution. The key insight for data leaders: in this new world, data quality cannot remain a background maintenance task. It needs to be the foundation every AI agent is built on — before a single workflow goes live.
Nowhere is this more visceral than in entity resolution — the problem of making sure your AI actually knows who it’s dealing with.
I have been watching this play out in real time across industries: “Agentic AI is the race car. Entity resolution is the track. You wouldn’t run a Formula 1 machine on gravel and expect to win.”
The examples are stark. In retail, duplicate customer records lead autonomous agents to dispatch multiple shipments, issue multiple offers, and trigger multiple refunds — quietly eroding margins at scale. In finance, fraudsters opening several accounts with small name variations go undetected because the fraud-detection AI treats each record as a separate person. In healthcare, a patient known as “Mary Chen” at one hospital and “M. Y. Chen” at a clinic becomes two different people in the AI’s world — and an autonomous care coordinator misses her allergy record before booking a procedure.
In each case, the AI wasn’t making bad decisions. It was making confident decisions on bad data. And because agentic systems are autonomous, they don’t make that mistake once — they repeat it hundreds or thousands of times before anyone notices.
Tools like Zingg — which resolve entities at scale across CRMs, EHRs, billing systems, and data lakes, running natively on Snowflake and Databricks — are becoming the kind of foundational data infrastructure that determines whether an AI deployment succeeds or silently fails. One bank that placed Zingg’s entity resolution layer beneath its fraud-detection AI saw fraud detection improve 4x — without changing the AI model at all. The model didn’t get smarter. The data it was reasoning on did.
That’s the new pitch data leaders are making — and it’s a powerful one. AI doesn’t paper over your data problems. It runs them at scale, in production, with consequences. Every dollar not being invested in data quality is a growing tax on every AI initiative downstream.
What This Means for Data Leaders Right Now
The opportunity is real and it is opening — but it requires a change in posture. Data teams have spent years learning to survive by making themselves useful to whoever controls the budget. The new play is positioning as the precondition for everything the business cares about.
Some practical realities for data leaders navigating this moment:
Your backlog is becoming a risk register. Every unresolved data quality issue, every undocumented pipeline, every inconsistent metric definition is a live failure point for an AI agent that will execute on bad information at machine speed. Frame your roadmap accordingly.
Entity resolution is becoming a first-class AI problem. Before an AI agent can act intelligently, it needs to know who it is acting on — and right now, most enterprise data lakes are full of the same customer, supplier, or patient under a dozen slightly different names. Deduplicating and resolving those identities isn’t a one-time cleanup job anymore; it’s an ongoing data foundation that every agentic workflow sits on top of. Teams that are investing in entity resolution infrastructure — using tools like Zingg to continuously resolve identities across CRMs, EHRs, and data platforms — are finding that their AI deployments perform dramatically better, without touching the models at all. The intelligence was always there. The data just wasn’t ready for it.
Data governance is becoming AI governance. The governance frameworks data teams have been building for years — classification rules, data retention policies, lineage tracking — are exactly what enterprises now need to keep AI agents grounded in reality.
The CDO is becoming a critical executive. The function that once reported to the CIO is increasingly driving the AI strategy conversation alongside the CEO and CFO.
The dbt Labs 2025 State of Analytics Engineering survey is already showing the shift: 40% of data teams added headcount in the past year — compared to just 14% the year before. Data budgets are growing too, with 30% of respondents reporting increases versus just 9% in the prior year. The most common complaint is no longer budget cuts — it’s that the team can’t keep pace with the business’s appetite.
As dbt Labs CTO Mark Porter put it directly: “As companies increase AI investments, leaders are prioritizing the teams responsible for data quality and governance — the essential foundation for AI effectiveness.”
The Table Is Turning
There’s something quietly satisfying about watching an industry vindicate itself not through persuasion, but through circumstance.
Data teams have spent years arguing that their work mattered. They built ROI frameworks and internal P&Ls and political coalitions. They embedded with business units and learned to speak in revenue terms. Some of it worked. Most of it was an uphill grind.
Now, agentic AI is making the argument for them — not through rhetoric, but through dependency. The most transformative technology initiative of the decade cannot function without clean data, governed pipelines, and trustworthy infrastructure. And the people building and maintaining those things are, right now, becoming central to the enterprise.
The data team is no longer supporting the business.
The business is starting to run on the data team.
If you found this useful, share it with a data leader who’s still spending Q4 justifying their existence to a skeptical CFO. Their moment is here — and it’s only getting bigger.
The entity resolution examples are the most concrete thing in here — and the most important. Fraud AI treating the same person as two records isn't a model failure, it's a data foundation failure. The model was doing exactly what it was designed to do. That distinction matters because it means more model investment won't fix it.
The "backlog as risk register" framing is the right posture shift. Every unresolved data quality issue is a live failure point for an autonomous system that will execute on it at machine speed, thousands of times before anyone notices. That's a completely different urgency than a dashboard being slightly wrong.
I write about production AI systems and distributed backends — the infra layer where these data quality decisions compound into retrieval failures and model drift. Worth a subscribe here too.