Agentic AI Is Only as Smart as Its Entities
And why I’ve seen smart agents make dumb mistakes — at scale


A few weeks ago, I was talking to a data leader at a fast-growing retail brand.
They’d just rolled out their shiny new AI marketing agent. It could segment customers, design campaigns, and send hyper-personalized emails — all without human intervention.
Two weeks in, the VP of Marketing noticed something strange. One of their top VIP customers had received three different “Welcome to our brand!” offers — each with a different discount.
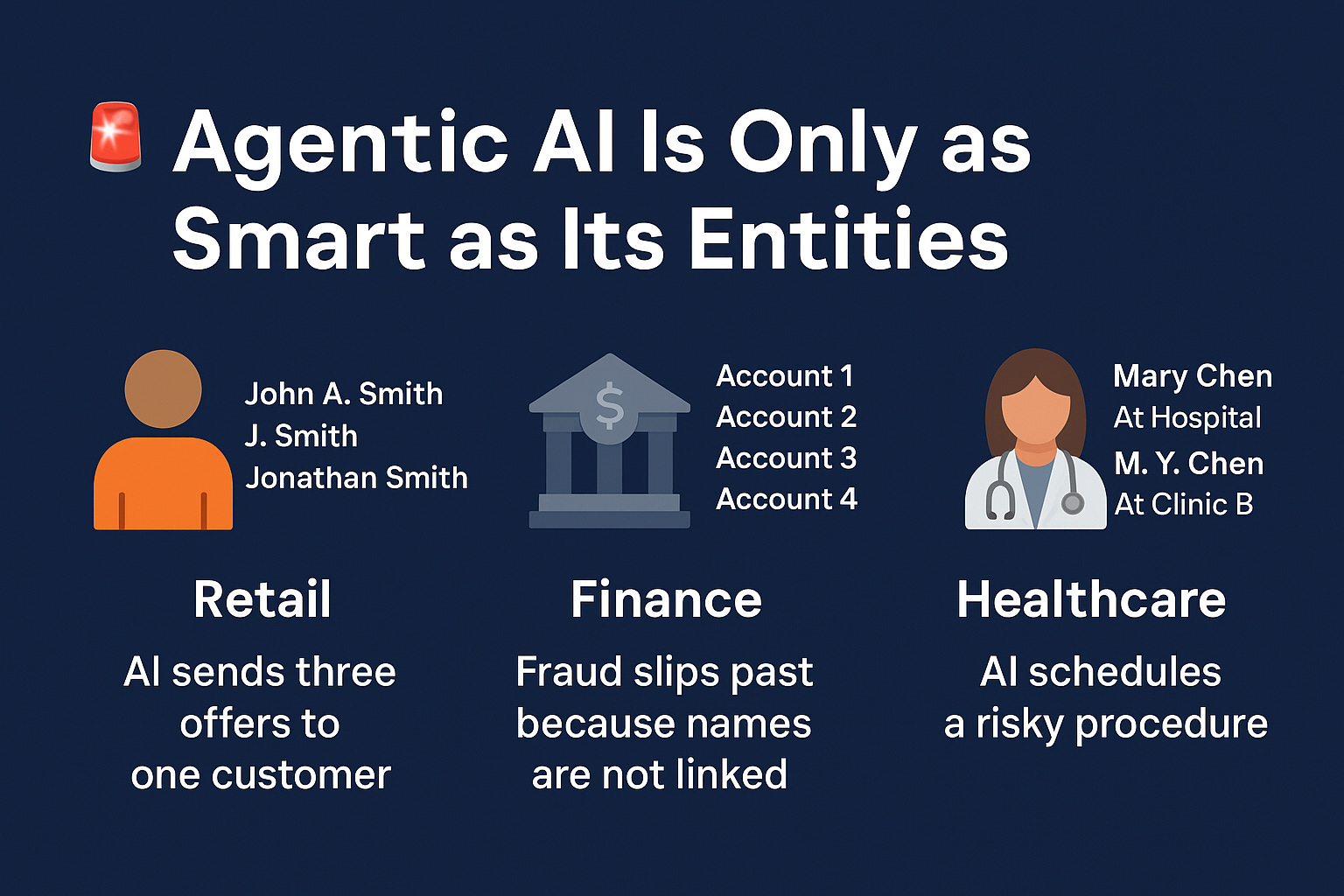
Turns out, their CRM had John A. Smith, J. Smith, and Jonathan Smith as three separate customers.
The agent wasn’t broken. It was doing exactly what it was told — treat each record as a unique person and delight them with a welcome offer. The problem? The records were wrong.
And this, I’ve realized over and over again, is where agentic AI stumbles: when the entities are messy, the automation multiplies the mess.
Over the past few years, I’ve seen this pattern play out in every industry:
Retail — Duplicate customer records mean multiple shipments, multiple offers, multiple refunds. Margins erode quietly.
Finance — Fraudsters open several accounts with tiny name variations. Without linking those identities, your fraud-detection AI treats them as separate people — and misses the pattern.
Healthcare — Patient “Mary Chen” at Hospital A is “M. Y. Chen” at Clinic B. An AI care coordinator misses her allergy record and books a risky procedure.
In each case, the AI wasn’t “dumb.” It was confidently acting on bad data. And because agentic AI is autonomous, it didn’t just make one mistake — it repeated the mistake hundreds or thousands of times before anyone noticed. Smart agents get the “who” wrong and this really hurts the business.
If you capture the hype, everyone talks about the cost of building and running agentic AI. Yet, fewer people talk about the cost of running it on messy data. Agents run on LLM calls, and every action burns tokens. When your entities aren’t resolved, the agent:
Processes duplicates
Repeats actions unnecessarily
Sends extra API calls trying to reconcile
Here’s the math from just one example scenario:
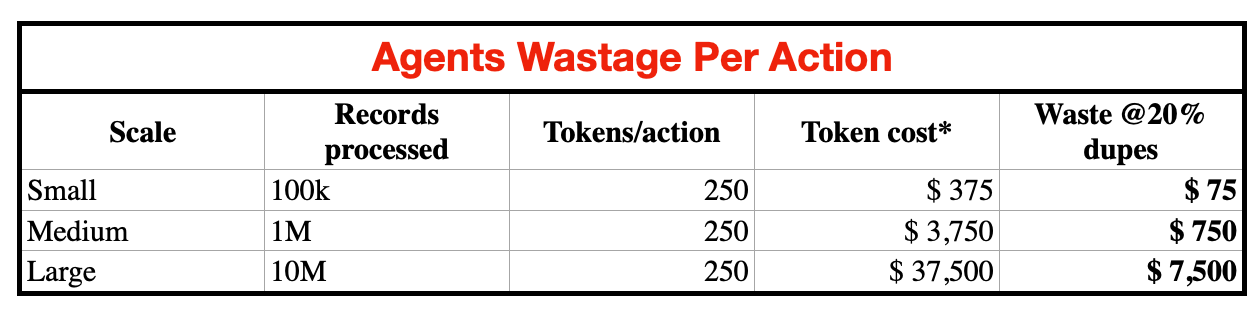
*Based on $15 per 1M tokens (GPT-4.1 tier).
Even with cheaper models, the % waste stays the same. That’s just compute waste. It doesn’t even include the cost of fixing the damage — reissuing refunds, restoring trust, or dealing with regulatory fallouts.
Why I care about this (and what we built at Zingg)
Before I started Zingg, I kept running into the same frustration:
We had amazing ML models, sophisticated rules engines, smart agents… but they were all reasoning on fragmented, messy entities.
At Zingg, we decided to treat entity resolution as a first-class product, not a one-off data cleanup exercise. That means:
Matching at scale across CRMs, EHRs, billing systems, and data lakes
Adaptive learning so the matching improves with every variation we see
Transparent decisions so you can explain why two records were linked
When customers put this layer under their agentic AI, they stopped paying for their agents to repeatedly do the wrong thing. In one case, a bank’s fraud detection improved 4x — without touching the AI model.
My advice to data leaders
If you’re about to launch an agentic AI project, take a breath.
Before you buy another GPU hour or fine-tune another model, ask:
“Do my agents actually know who they’re dealing with?”
Because in my experience, agentic AI is the race car. Entity resolution is the track.
You wouldn’t run a Formula 1 machine on gravel and expect to win.
P.S. If you’re curious about what we are building at Zingg, or have war stories about entity chaos in AI systems, I’d love to hear from you.
We fully agree with the perspective that Agentic AI is only as intelligent as its entities, and entity resolution is a key 'track' for any 'Formula 1 car.' In our experience, the problem lies not with the agents themselves, but with the architecture that underlies knowledge management. We would be interested in whether you are exploring solutions that are radically different from those based on vectors, which, as research shows, have inherent limitations in terms of structure and provenance. We believe that it is precisely in these different foundations, such as hypergraphs, that the potential to overcome the chaos of entities and achieve truly reliable results lies.