Zingg Incremental Flow
because data changes, and the identity graph should keep up too!

As a startup founder and someone who actively follows companies doing interesting work, I often wonder about the levers behind a viable and thriving business. One thing that comes up repeatedly is Growth.
From the point of view of data teams in a fast growing business, what really does growth amount to? How does it manifest in the day to day data collection and processing?
If we dissect the key activities happening across businesses during the growth phase, there are a few commonalities that stand out. New customers get acquired at a fast pace. Existing customers buy more products and services. They also buy from additional channels, like a website, if they earlier only bought from the brick and mortar store. The business keeps in touch with existing customers and makes sure it has the ways and means to contact them with offers and product updates. Customers inform the business when they move or change jobs. Strategic mergers and acquisitons happen. Additional procurement of products and services happens to fuel the growth and new suppliers get onboarded. New product lines are introduced and additional customers onboarded.
Thus, data about core business entities - customers, suppliers, products and parts starts changing rapidly. New entity records get added, existing ones get updated. Some of the records are deleted.
A small detour before we go any further. In my last post, I discussed about the cross reference and persistent ZINGG_ID. Let us recap a bit. When we build our customer journeys, segment users and attribute acquisition to campaigns and channels, we need a consistent view of the customer data. We want to associate an identifier that inherently represents the entity. And we want to use this identifier in all our reporting and analytics, as well as operational systems. If a customer gets in touch with us at the call centre, we want to use the ZINGG_ID to get the context of their purchases and their relationship with us.
Coming back on the current topic. There is immense business value in having a persistent and continuously updated identity graph for each of the downstream usecases like marketing attribution, personalisation, life time value, fraud and risk.
However, as we saw earlier, in a growing business, records are no longer static. They are getting added and deleted and updated. So, how does all this change affect identity resolution? New records would start matching with existing ones. Updated records may start matching with other records they did not match with earlier. They may stop matching with records they matched up earlier. Hence clusters of resolved identities are evolving with the data. They are merging or splitting and new ones are created all the time.
Let us dig deeper how that looks by going over some examples.
In the following dataset, the records with ID rec-1020-org-incr and rec-1023-org-incr have been updated during business operations and continue to exhibit strong similarity with their original matches. Two new records with ID rec-10000-org-new got added, matched with no other existing record but with each other.
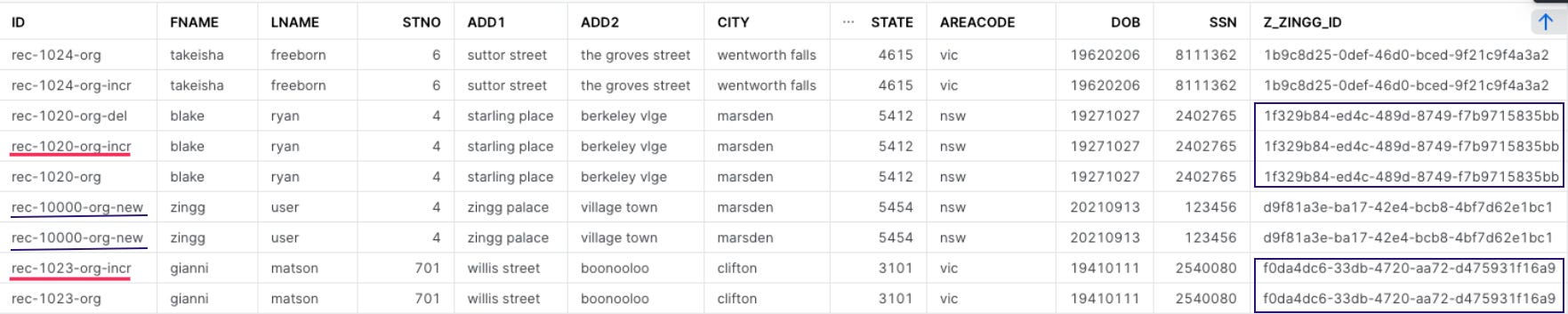
With me so far? Now, here comes an even more interesting bit! In the following dataset, rec-1022-org and rec-1022-dup-4 had matched originally.

In an update at a later date, rec-1022-dup-4 got altered and these records now stop matching with each other. This usually happens in the case of wrong data capture in an original record.

Thus, when a record is updated yet it is close enough to the original cluster values, we ought to keep the cluster relationship. In the case of adding a new record that does not match any existing ones, a new cluster should get created. When a new record shows up that matches an existing cluster, the new record has to get attached to the cluster. When a new record that matches two clusters is passed, the clusters need to get merged. If we make edits to a record so it no longer matches with its existing cluster and then reverted those edits, the models should correctly track the updated and reversed entry, with the record remaining in the correct cluster throughout the incremental runs. There are myriad possible scenarios of clusters splitting and merging with each other. Matching new and updated against existing records gets extremely complex before we realise.
Technically, we could run a full match with Zingg Community version on the updated dataset and get the new clusters.
But.
If we run the entire matching process again, how do we preserve the persistent ZINGG_ID for the records? How do we tie back the newly generated ZINGG_IDs on the updated set to the original ZINGG_IDs? Especially when a new cluster will now have multiple older ZINGG_IDs, or when a new cluster may have some old different ZINGG_IDs and some fresh ones. How do we choose the surviving ZINGG_ID? On top of that, running full matching loads on growing datasets is costly in terms of time taken and compute.
Here is how we handle this in Zingg Enterprise.
Clusters automatically merge, unmerge and new clusters with ZINGG_IDs are created based on new and updated values while only matching the updated records.
Which means that
The identity graph stays updated even when the data changes.
When I had open sourced Zingg, I felt that it was my life’s best work and wondered if I would ever work on anything more challenging. While building the incremental update, I realized that this functionality is way way tougher to build than everything else I had built so far. Magnitudes tougher than the active learning aspects of Zingg, or the blocking model. There are tons of algorithmic and performance aspects to consider. Even chalking out the test strategy and test data proved to be quite a challenge.
After intensive testing on internally generated datasets, we released the runIncremental phase to our early customers. We knew our test data could not mimic every possible scenario, and though we were confident of the algorithms, we suspected edge cases which we had not envisaged. We requested our customers to test the incremental flows on their data and to report any inconsistencies in matching or cluster assignment. We were thrilled to get an extremely positive response!
Here is an excerpt from one of their test reports:
Each test scenario was carefully constructed to challenge the model and verify the expected behavior. The results were consistently positive, demonstrating the model's precision and adaptability in every test case. Its ability to accurately handle minor data modifications and correctly process entirely new, atypical entries was particularly noteworthy. Equally impressive was its capability to manage entries that aligned with several clusters without compromising accuracy and its efficiency in reverting changes to their original form.
The success of these tests is an essential step on the way to releasing the incremental Zingg models in production.
We are super proud to have come so far, and happy to roll it to all our customers. If the idea of an identity graph on your own data within your own data lake and warehouse appeals to you, why not hit reply and let us grab a coffee? :-)