The Semantic Layer Does Not Have All The Answers
Why "what does revenue mean?" doesnt help "who is this customer?"

A few months ago, I was in a conversation with a data architect at a large enterprise company. They had just finished a significant investment in their semantic layer. Metrics were defined once. Every tool — BI dashboards, SQL notebooks, their new AI agent — queried against the same definitions. “Revenue” finally meant the same thing everywhere.
It was a real win. They were proud of it. And rightly so.
Then their agent started acting on customers.
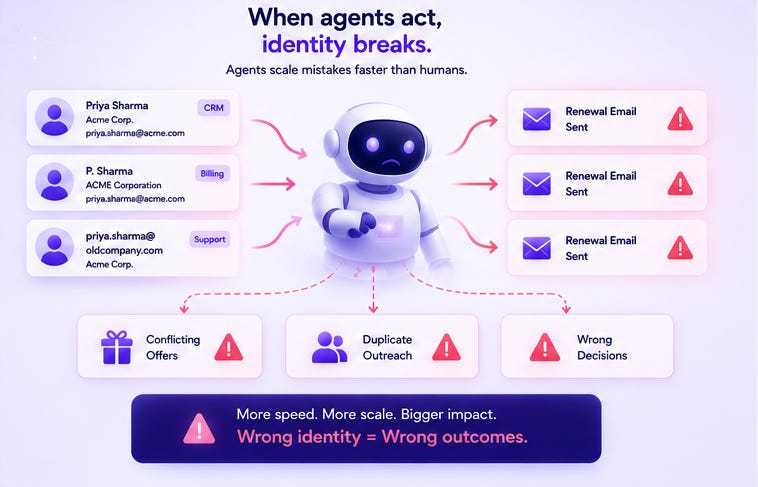
It was supposed to send renewal nudges to accounts that hadn’t logged in for 60 days. Simple enough. Except the agent was working off a customer ID that wasn’t clean. The same enterprise account appeared in the CRM as three separate records — slightly different company names, slightly different contacts, same domain. The agent sent three separate renewal sequences to the same account. The account manager got an angry call.
The semantic layer was perfect. The entity underneath it was broken.

The two questions data infrastructure needs to answer
There are really two different kinds of questions your data stack needs to answer.
The first is a definition
What does “active user” mean? How do we calculate churn? What counts as revenue? These questions have answers. Someone writes the YAML, someone reviews the PR, the definition gets committed. Deterministic. The semantic layer is built precisely for this — and the ecosystem around it (dbt, MetricFlow, Cube, LookML) has matured enormously.
The second is a definite value
Who is this customer? Is the “Priya Sharma” in your CRM the same as “P. Sharma” in your billing system and “priya.sharma@oldcompany.com” in your support tickets? That question doesn’t need a definition. It needs a definite answer. And no amount of metric definition answers it.
While building semantic layers, it is easy to assume that they will answer everything. For most of the last months of the agentic rush, that assumption was manageable — agents were mostly querying, not acting. But now, agents are acting. And the assumption that we have clean entities is cracking.
When agents query vs. when agents act
Think about using AI agents for querying high level information. “What was APAC revenue last quarter?” The semantic layer handles this well.
The next generation of AI agents is different. Agents are taking actions on behalf of businesses — sending communications, flagging accounts, triggering workflows, making decisions per customer. Now the customer ID has to mean something specific. It has to map to one real-world person, consistently, across every system the agent touches.
Let us see how this plays out across industries:
Retail — An agent personalizes offers per customer. Duplicate records mean the same customer gets competing offers. Margin erodes. The customer is confused.
Financial services — A risk agent monitors accounts for suspicious patterns. If the same individual is fragmented across three records, the pattern never surfaces. The agent sees three clean records instead of one risky one.
Healthcare — A care coordination agent tracks patient history. “Maria Santos” at one clinic is “M. Santos” at the specialist. The agent misses the allergy note. That’s not a data quality problem anymore — that’s a patient safety problem.
In every case, the agent is doing exactly what it was designed to do. The entities beneath it are what’s broken. And because agents move fast and act repeatedly, they don’t make the mistake once. They make it at scale, before anyone notices.
The piece most context stacks haven’t made agent-ready - MDM
Master Data Management has existed as a discipline for decades. The idea is straightforward: maintain a single trusted record for every customer, product, account, location. Know that these three records are all the same person. Keep that knowledge current as data changes.
In practice, MDM has lived inside expensive enterprise software, long implementation cycles, and governance teams. It was built for periodic batch reconciliation. It was never designed to be queried by an agent at runtime.
That’s the gap I keep running into. Not that MDM and entity resolution doesn’t exist as a discipline — it does, and people have been working on it seriously for a long time. The gap is that a resolved entity graph hasn’t been made agent-ready in the way that metric stores have. Single source of truth for humans and agents. API-accessible. Continuously updated. Queryable at the point of action.
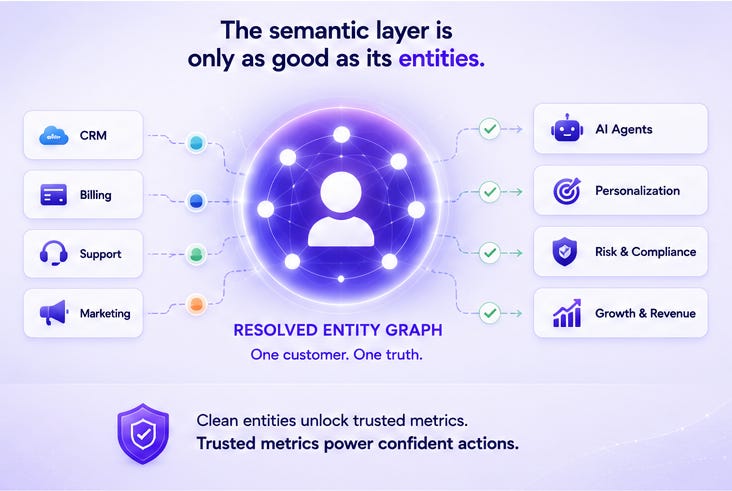
The semantic layer is only as good as its entities
Here’s the part that doesn’t get said enough: the semantic layer depends on this problem being solved.
The customer ID is the join key that makes your semantic layer useful. It connects revenue to behavior, behavior to support history, support history to renewal risk. The entire model assumes that when you say “customer,” every system is pointing to the same real-world person.
If the entity graph is wrong, the metrics are wrong — even if every definition is perfect. You can define revenue with mathematical precision and still be measuring it for a customer population that’s partly duplicated, partly fragmented, and partly imaginary.
The semantic layer is foundational infrastructure. The resolved entity graph is the layer giving it strength. Most stacks have invested heavily in the first. The second is still treated as a cleanup task, a data quality ticket, something to handle later.
As agents move from answering questions to taking actions on real customers, accounts, and products, this “later” treatment will be the difference between agentic success or failure. It is time to invest in the entity layer today!
Are you seeing this in your stack? I’m curious how teams are approaching entity resolution today — whether through MDM tooling, home-grown pipelines, or something else entirely. Would love to hear what’s working. Hit reply or comment below!