From Half A Day To Half An Hour! Performance Tuning Snowpark For Identity Resolution On Snowflake
Scaling to millions of records on the x small size warehouse

We have spent the last few weeks on the Zingg Identity Resolution product for Snowflake by battle-testing it for deployment and scale. Built as an entry for the Snowflake Challenge and on top of the Zingg Open Source version, we already had a pretty solid application that could resolve entities at scale within Snowflake. So we did not expect any major hiccups in terms of the overall flow, model building, and prediction. Developer confidence, bolstered by feedback from users you may say ;-) However, since the product leverages Snowpark instead of Spark, we did expect a bit of performance tuning here and there. In this post, I wanted to share the challenges we faced and the changes we made to overcome them. Hope this is useful to others building on Snowflake.
To begin with, we had a 500k test record set running on the x-small size Snowflake warehouse in roughly 12 hours. Though the code was not tuned for Snowflake performance, the job ran successfully to completion without hiccups and we used this as our baseline. Entity Resolution is a tough problem, and harder to do at scale. We want to get maximum mileage out of Snowflake and ensure Zingg ran efficiently for our customers. Our philosophy is that the customer should not have to pay the computing bill for any inefficient code. Hence we always aim to extract maximum performance without throwing more hardware at the problem. Unless we absolutely have to. We also had a target dataset of roughly 2.5 million records, 5 times the baseline. This was a real customer dataset, with non-uniform distribution across fields and with triple the columns of our test set. When we do entity resolution, a 5-fold increase in the input with the same number of columns and match types leads to a 25-fold increase in the comparison complexity. As we have robust index learning based on training data in Zingg along with tons of performance optimizations, we expected the matching job to be somewhere close to 18 hours, which we were planning to tune. However, when we ran this dataset on the x-small Snowflake warehouse, we started seeing errors on session timeout intermittently after roughly 8 hours.
com.snowflake.snowpark.SnowparkClientException: Error Code: 0408, Error message: Your Snowpark session has expired. You must recreate your session.
Authentication token has expired. The user must authenticate again.
Authentication token has expired. The user must authenticate again.
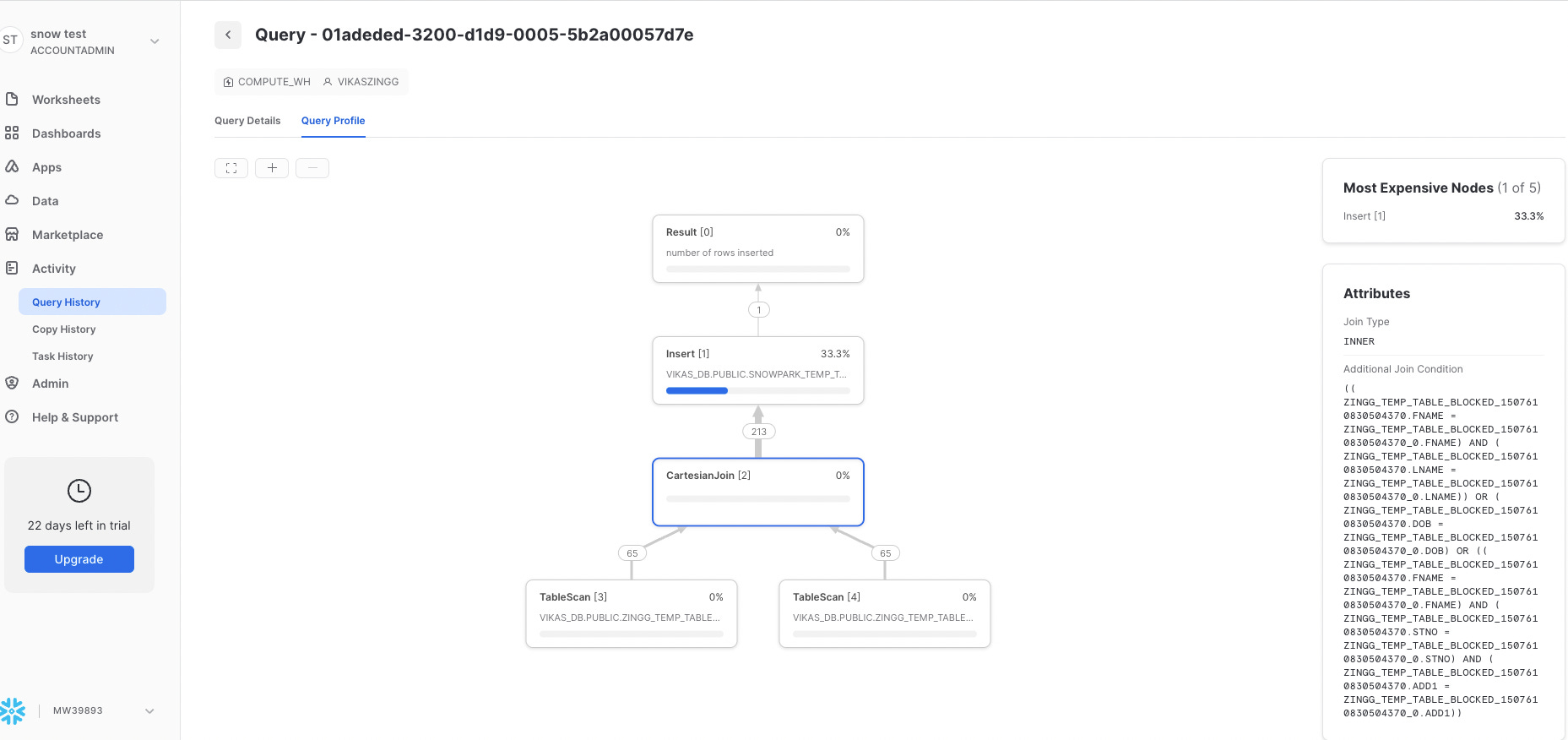
Running the Snowpark client as a background process or with nohup helped, and we were able to see the job continue to run beyond 24 hours. Surely this performance was not something we wanted to ship. So we killed the run after identifying the first set of bottlenecks. Our approach was to zero in on the hotspots and solve them surgically in the order of highest impact first. The highest impact was mostly about the functionality taking maximum time, but in some cases, we also fixed stuff that was earlier in the flow but slow enough to not let us go past a particular stage in a reasonable time. We used the query profiler by Snowflake extensively for understanding and improving the flow, along with some traces and timing logs in our own code base. The query profiler gives a lot of valuable statistics about the query plan, function timing, and which part of the code triggered the query. It also provides partition-level and row-level information, so it was our go-to source for hotspot identification as well as figuring out if our changes worked as expected. Here is a snapshot of how it looks.
At a high level, here is how the Zingg flow is structured:
Input Data → Index → Join On Index to get Approximate Similar Pairs → Pairwise Similarity Features → Predict Matches → Graph Processing
We learn an index on the input data to create approximately similar pairs. We then compute similarity features on these pairs and predict if the pair is a match or not. This output is clustered using graph algorithms to convert matched pairs to clusters.
Our logs indicated that the biggest bottleneck was the Predict Match flow. The. predict flow leveraged a Snowpark user-defined table function to return two columns. The first was if a given pair was a match or not. The second was the score indicating the similarity of records in the pair with each other. The higher the score, the better the match. Since we returned more than one value from this function, we built it as a UDTF instead of a UDF. However, this UDTF was consuming the bulk of our processing time. Given that we were not really creating multiple rows per input row but returning multiple values per row, all the lateral joins we saw on the query plan did not make sense. It made a worthwhile experiment to convert the UDTF to a user defined function, concatenating the prediction and the score in one value and extracting them out through another UDF. This worked like a charm and immediately cut down the processing on our baseline dataset from 12 hours to 5 and a half hours. More than a 2x improvement! This was a massive gain, but we clearly had more work to do.
We then set out to optimize the queries generated by Snowflake through the Snowpark code we had written. The bottlenecks here were mostly while indexing and generating the near-similar pairs. We saw that if we did computations on a Snowpark Dataframe to build the index and then self-joined the Dataframe on the index, the index computations were repeated. This was counterintuitive to us, as we were using the same instance of the Dataframe. We tried to clone the Dataframe as advised but that did not work. Finally, when we cached the Dataframe, the query plan was altered and our costly computations happened only once. The lesson here was that if the computation is costly and the Dataframe has to be used in a self-join, it is wise to cache the intermediate results. However, this has to be used with caution, as there is an overhead in temporary table creation and disk spillage.
Another optimization we did was on the range scan. We join the records on the computed index to build the pairs. To avoid pairs like Record A, Record B repeat as Record B, Record A, we filter out the pairs on ids. This is critical as the subsequent similarity feature processing is expensive. However, we saw that the join became a cartesian join with filtering pushed out to much later in the flow. This led to slow performance along with a suboptimal flow, making similarity feature computations that we did not need. We cached the Dataframe arising out of the join and changed the id1 > id2 range query to id1-id2 > 0, which pushed the filter at the right junction for our flow as well as changed the earlier cartesian join to a normal join.
Together, the above changes shaved off roughly 20% of runtime on our baseline dataset, and we were now down to 4 hours and 30 minutes of the entity resolution workflow on 500,000 records.
With these major fixes in, we profiled the run again, closely looking through the hotspots, and to our utter dismay, found that the predict function was still the most time-consuming part of the entity resolution workflow. This is a Python UDF that uses machine learning for the prediction. A pre-built model learnt from the training data is passed as an argument to the function along with multiple similarity features of the pair. This UDF predicts whether the pair is a match or not along with their similarity score. Since the features are different for different datasets, we do not know beforehand the shape of the feature columns. Hence we construct an array over the multiple features so that we can resolve different types of entities. In a good bad way, there was no code change we could do to optimize this function. Our code was concise and to the point, and there wasn’t anything to shave off here. So we focused on the Snowflake invocation of this UDF. We learned that Snowflake advocates vectorizing UDFs, especially if they involve matrices and other machine learning workloads. The vectorized UDFs are passed batches of rows, and return batches with results. This made immediate sense as invoking the UDF row by row was surely not going to help with the inherent matrix manipulations. Though we wanted to do this right away, there were quite a few challenges.
It was difficult for us to define the function signature as the column number and types were dynamic. Earlier we used to pass an array, so it had worked. After some thought, we were able to build the signature and define the function on the fly using the metadata we already had while creating the similarity features. Passing the model became tricky however and we were not able to deserialize it in the function no matter what we tried. It seemed there were some extra bytes added when the model was passed as a column received by the UDF as part of a Pandas Dataframe. The same code had been working earlier row by row, so the conversion of Snowframe Dataframe rows to Pandas Dataframe internally seemed to be the likely cause. There was another complexity. We were invoking the Python function through Java Snowpark API, so there were too many layers to unravel here. We went over the open-source code of Snowpark, we tried to add function logging and tracing, we tried to debug calling the UDF from Python, and we read all that we could..we pretty much did anything and everything we could think of!
After struggling for a few anxious days, we changed our approach and began persisting the model to a Snowflake stage. Our UDF would import that location and read and use the model. This finally solved the serde issue we were seeing earlier, along with reducing the data sent to the function. In hindsight, we should have tried this approach first, but at that time the thought was to only change what was absolutely necessary. The code for passing the model had been working for a while, and while tuning performance, it is important to control the changes. So we weren’t too wrong either.
It got a bit late in the day when we ran the build with these changes, and when the test dataset ran in half an hour, we were sure something was crazily wrong. Maybe we had left the bulk of our processing code commented out in the run by mistake? We saw the output table, the results were there, and the predictions looked accurate. It was hard to believe. Too weary to think further, we called it a day.
The next day we double-checked the output and everything was in order. We cross-checked. Yes, it looks fine. No, we are not sure. Not yet. Let us run it once more. Boom, the job was finished by the time we finished our daily catchup + coffee.
28 minutes. From 12 hours. From half a day to half an hour! 24x.
On an x-small warehouse resolving identities across multiple columns for 500,000 rows. Wow! High Five! Now we need a break. Mission Impossible Dead Reckoning, here we come!
It was now time to run the customer data set in their warehouse. Brimming with confidence, we fire the job and monitor it from time to time. Umm..it is not working. The predict function is still a bottleneck. For some reason, the batch size Snowflake has automatically chosen on this dataset is 10, while it was sending 1000 rows at a time to the function on our test data. Possibly because there are way too many columns here compared to our test data? The batch size hint is just a hint, but that seems to be the only ammunition we have right now. Will it work? So we modify the UDF and add the max batch size annotation. This has the desired effect, and we have some great results for our customers.
There were a few other changes we had to make to get here. For example, the Dataframe.show() function would cause an out of memory error on the client machine if the data was big. While working on performance optimization, it is critical that functional parts of the code work flawlessly. We had used show() liberally in our code to verify the logic, assuming that it would limit the records sent to the Snowpark client by limiting rows in the warehouse itself. But show() works differently. It fetches everything to the client and then truncates to 10 rows. This was a bit counterintuitive, but an easy fix.
Overall we are super excited about the gains we have made and so happy that we have come this far. We hope the lessons above will help folks who are building on Snowflake and Snowpark. Feel free to talk to us if you are struggling with Snowpark/Snowflake performance issues, we would love to help and share our learnings! And if you know someone who needs entity resolution on Snowflake, please do send them our way :-)
Ciao!