Build, Learn, Repeat
Lessons learnt in the cloud journey

Open source teaches you so much! Here is one really big learning for me over the past few months.
As Zingg leverages Spark, cloud-based Spark environments like Azure and Databricks are natural run times for Zingg. My thought while building Zingg was that as long as we bundle our dependencies properly, the entity resolution jobs would run seamlessly on all the different Spark offerings. Only the invocation methodology to run Zingg would differ between a hosted Spark service and a private Apache Spark cluster. To be absolutely certain of this, I ran Zingg matching on the Databricks cloud platform. Since the Azure Spark offering encapsulates the Databricks platform, running on Databricks would cover both. With this test successful, I focused on the core building blocks for entity resolution and went ahead with my open-source plans.
Hence, it was quite surprising to me to see that one of the earliest GitHub issues reported was on running Zingg on Azure/Databricks! I got curious - what could have gone wrong? Probably I had not documented the steps properly. I also felt a little bad that the instructions I had put out to run Zingg on the cloud were off the mark. So, I ran the cloud tests again right away and tried to make sure that I got the documentation right this time. Pretty pleased, off to other stuff!
I forgot this episode for a few weeks, working on other features requested by users which made using Zingg easier. And then the issue got reported again, things were still not working :-( What could be wrong this time, I thought? From my tests, I clearly remembered that the job had run successfully in the Databricks cloud. My synopsis was that I had likely made a mistake while copying over the cloud configurations from the web interface. I attributed this to being a command-line fan who mostly refuses to click buttons. With a mental note to myself to do better next time, I carefully copied over the instructions this time more diligently. And that is when epiphany struck! I realized that I had completely missed testing our most important thing on the managed Spark cloud - the interactive labeler to build the training set!
Some background here - Zingg builds machine learning models for entity resolution. As training data is needed to create these models, Zingg ships with a console-based labeler that chooses a few representative samples to the user which she can mark as matches and non-matches. This user input is used to build and tune the underlying blocking and classifying models. Here is the interactive labeler in action.

This labeler runs on the Spark driver machine. In our development tests and with all the users we have worked with, we have always had access to its shell prompt. Now, here is the catch - Spark on the cloud exposes the driver logs but not the prompt through which the job is being run. One can log in to the driver machine separately, but that doesn’t give access to the console of the running program. This is fair, the Spark jobs are supposed to be long-running and are not for accepting inputs. However, in our case, this means that the Zingg labeler is not an interactive interface in the cloud but a mere display of the first sample Zingg wants the user to mark.
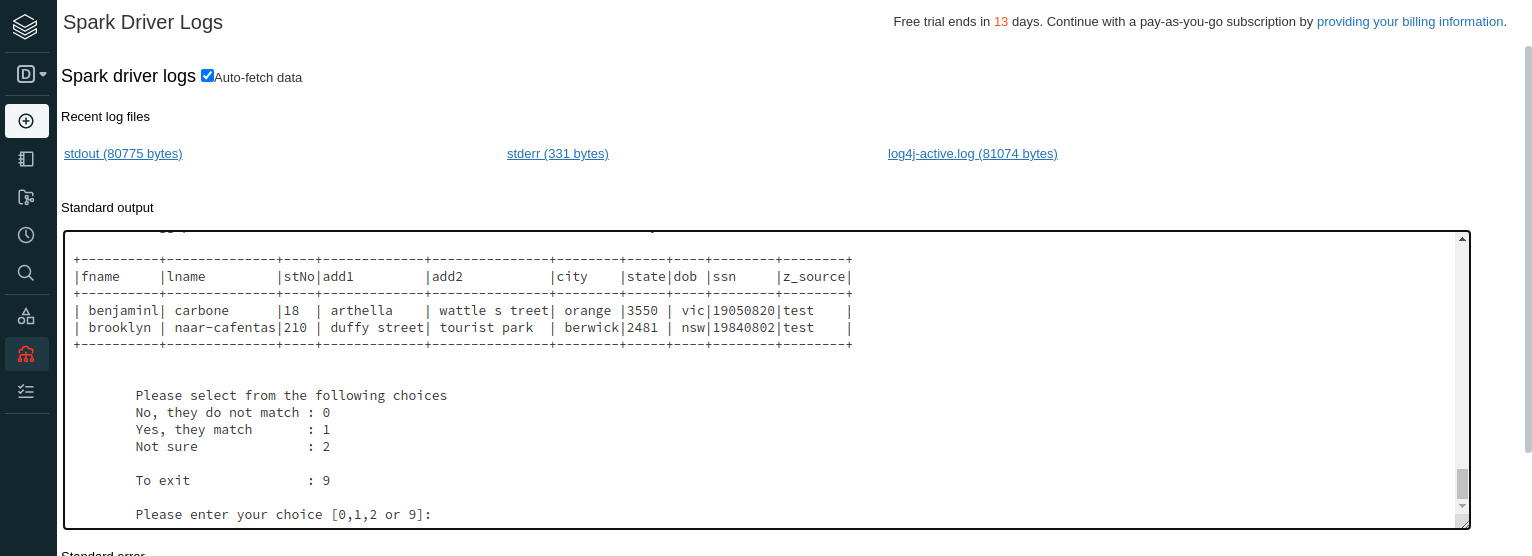
As you can see above, there is no way to accept user feedback or loop through the remaining samples Zingg has found. Gosh, if there was a rock I could hide under! How did I miss this?
As part of my testing, I had used one of the existing example models and did the drill…I had not built an entity resolution model from scratch and tested each Zingg phase. At that time it made sense, the testing was geared towards the packaging and the right cloud configurations. I was focused on the file systems, the data sources, and the right way to pass parameters to the Zingg job. As I tested the matching which is the final step, I verified the results and hence I confidently published the recipes in the documentation. It felt ok to assume that the other Zingg phases would work as seamlessly - after all we are just passing different parameters to the same program.
This was such a blind spot :-(
So, now, what should we do? As there were some users waiting to try Zingg on Databricks, my first step was a quick and dirty PySpark script in a Databricks notebook where the user would go over the displayed edge cases in a table and manually enter the sample record ids of matches or non-matches. Something like the following image

This got the job done and the end-user gave a thumbs up!!!

But, I was not at all happy with this approach where the ids of the samples in the matched clusters were provided by copy pasting them out. It was fairly time-consuming and required a lot of effort from the user.
With Zingg, I have been working towards cutting-edge AI - active learning, semantics, automated cleansing, and here I was delivering a list of records from which the user had to manually copy over the ids and repeat this process for matches, non-matches, and not-sure samples. We wanted flying cars, but we got ....
I was determined to do better.
As I got the chance to work with the Databricks team for this integration, I luckily had the experts for feedback on possible approaches. The Databricks team has some of the smartest and the friendliest people I know, and they really helped me a lot here. There were two ways we could go. The first way was to
Let the user run the Zingg Spark job in the cloud to select pairs for labeling. As this process weeds through a lot of samples to minimize user effort in labeling, it can get compute-intensive with growing data. Thus Spark is a necessity here.
Then, use file copying utilities to copy over the Zingg sample records and run the interactive labeler on the local machine. This doesnt really need a Spark cluster since the sample data to be marked is pretty small.
Next, copy over the labeler output back to the Databricks File System
Repeat
This was an easy route, writing small scripts to automate the copying was not going to take too long. But, there were some drawbacks - the user would need to set up a local Zingg environment and we had increased the steps needed to get from raw data to resolved entities.
The second route was to have a new labeler run natively within the Databricks environment. This meant more work for us but a far better experience for the user. Making work easier for our users is super important to me, and hence we started working in this direction. Here is what our first attempt at the notebook-based labeler looked like. This eliminated manual cluster-id entry as we used the Databricks textbox widgets to accept user input. Thus, the user could simply enter their choice about the pairs to build the training set.

Unfortunately, this approach had an inherent latency as we used Spark for reading and writing these very small files, and the cluster startup time hurt the user experience. Spark is built for large-scale data processing, it does unbelievable things at scale. Hence running our labeler kind of read-write interactions in Spark is a poor design choice. After much deliberation, we have now modified this approach to a Pandas based approach. We are using the combo box widget provided by Databricks to accept user feedback on the displayed pairs which makes the interaction look like this:
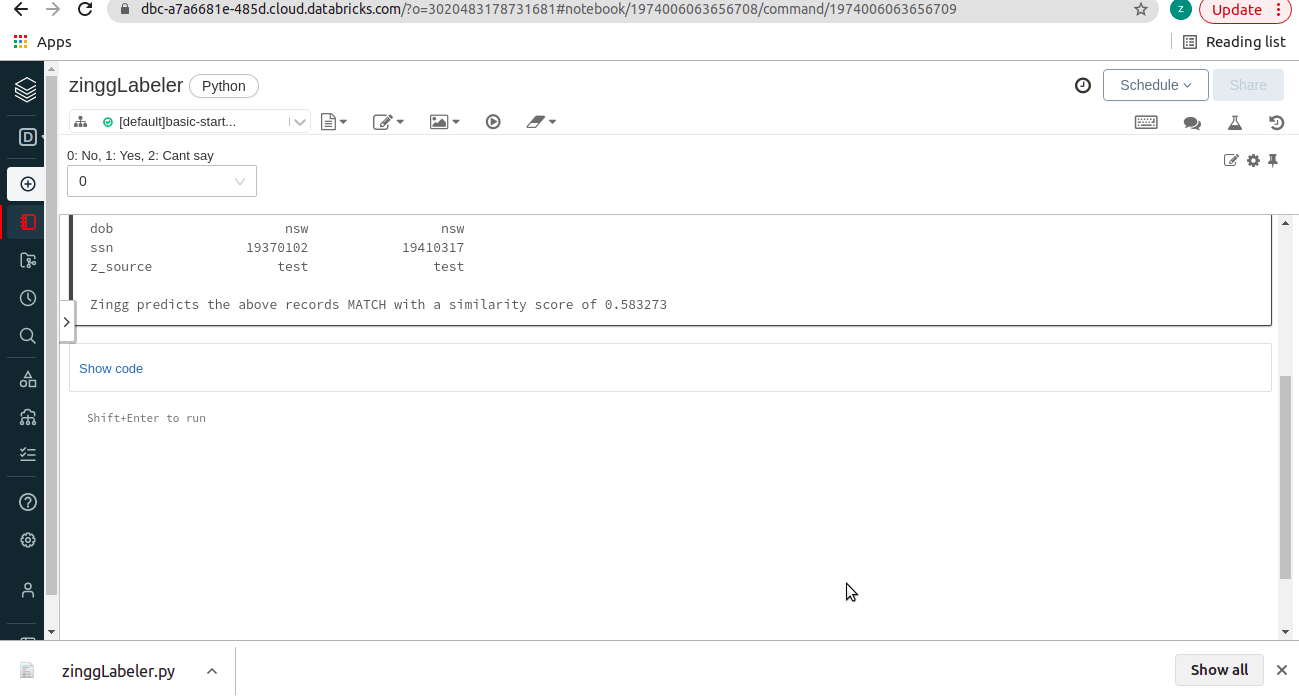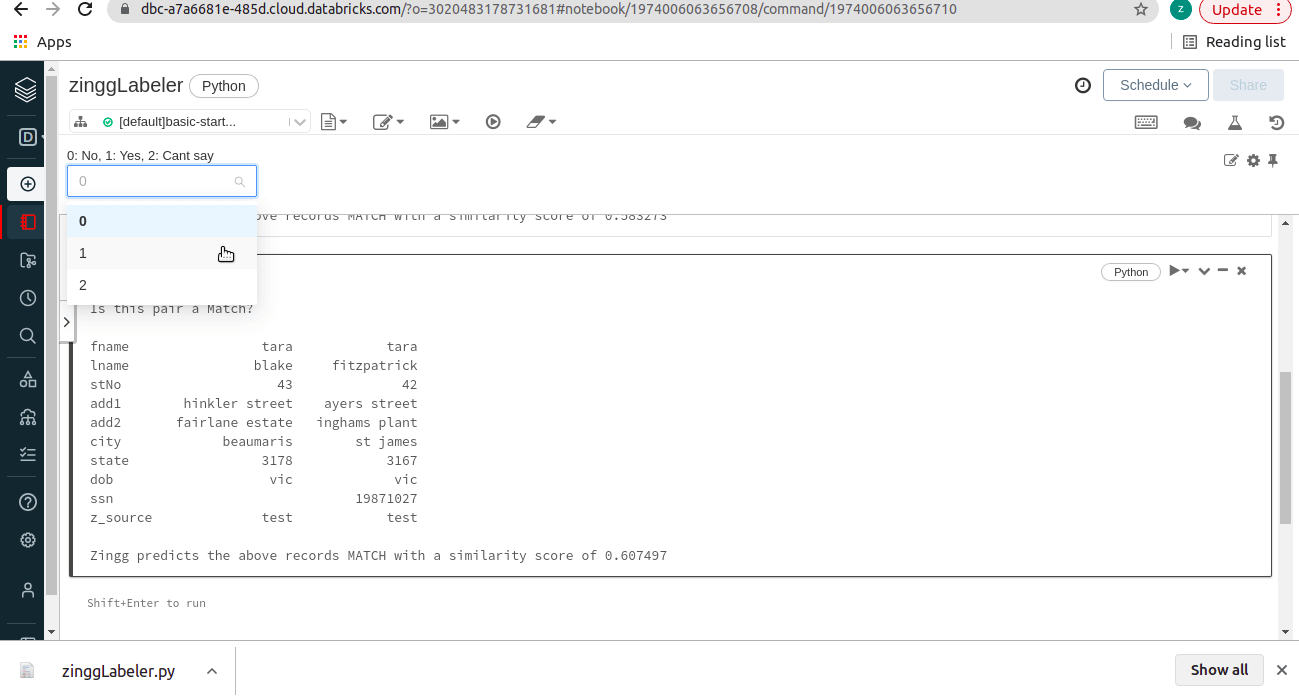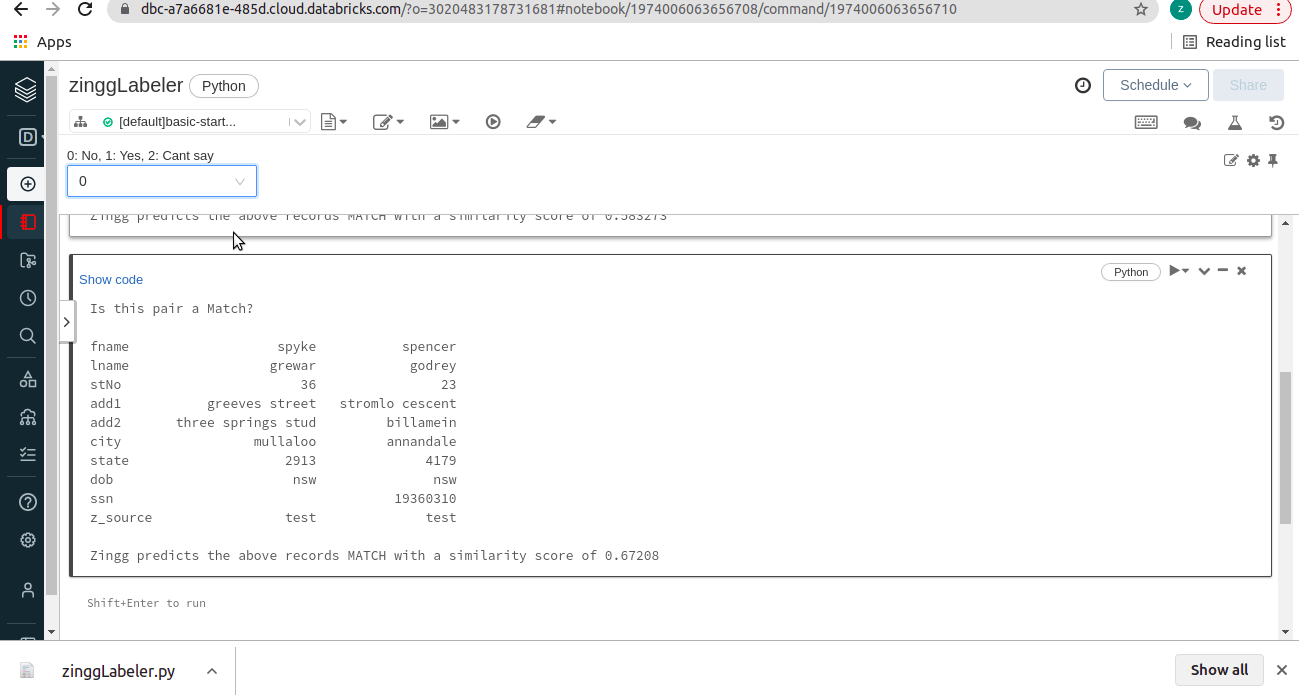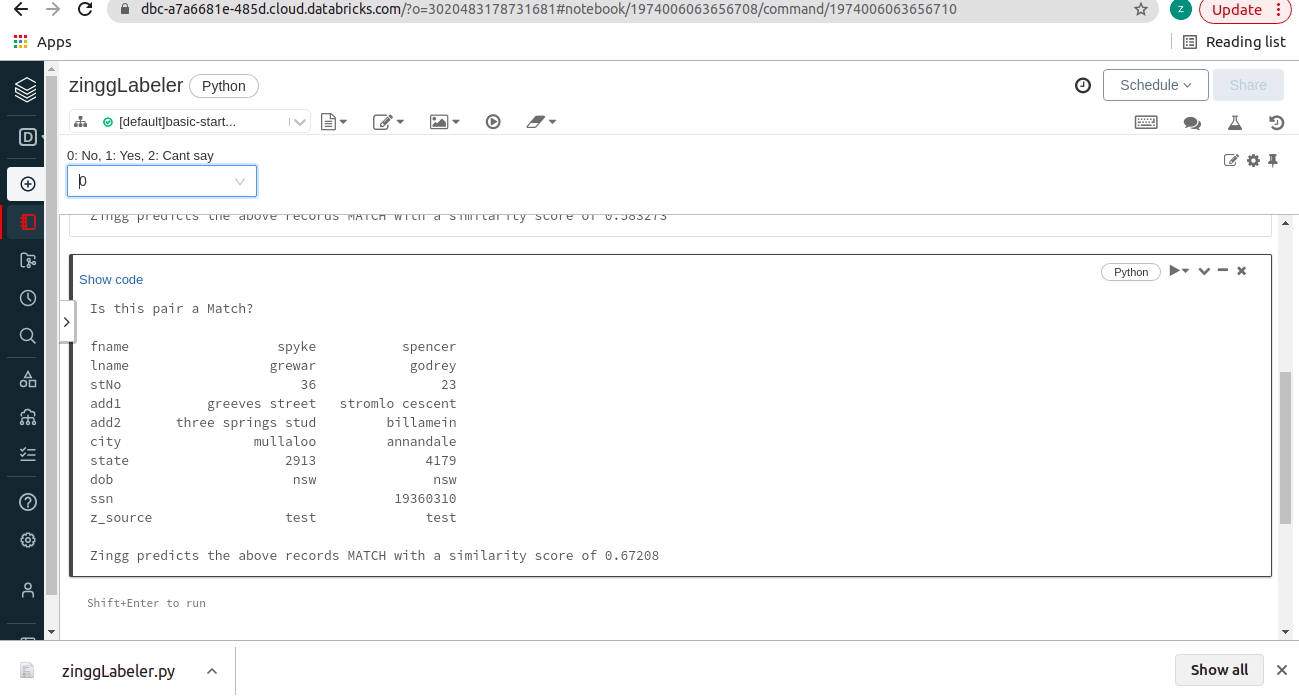
This makes the labeler as interactive as the original console labeler, and it runs like a breeze!
I feel this is a major improvement over our earlier versions and I am pretty excited to share this with our users. We still have a few rough edges, but it is a step in the right direction.
In the long term, I would love for us to have a unified interface to support all the cloud environments - Snowflake, Databricks, Azure, GCP and AWS. And also for graph databases and other systems.
If you have any comments on this approach, I would love to hear your thoughts here or on Twitter or the Zingg Slack.
I am also looking for teammates who like working on such problems. If you think that is you, let us chat!