Before You Build a Knowledge Graph, You Need to Solve Identity

A financial services team I know spent nine months building a knowledge graph. The use case was compelling: link entities across counterparty risk data, beneficial ownership filings, and internal CRM records to power a new compliance analytics layer. They ingested data from six sources. Modeled the ontology carefully. Built the pipelines.
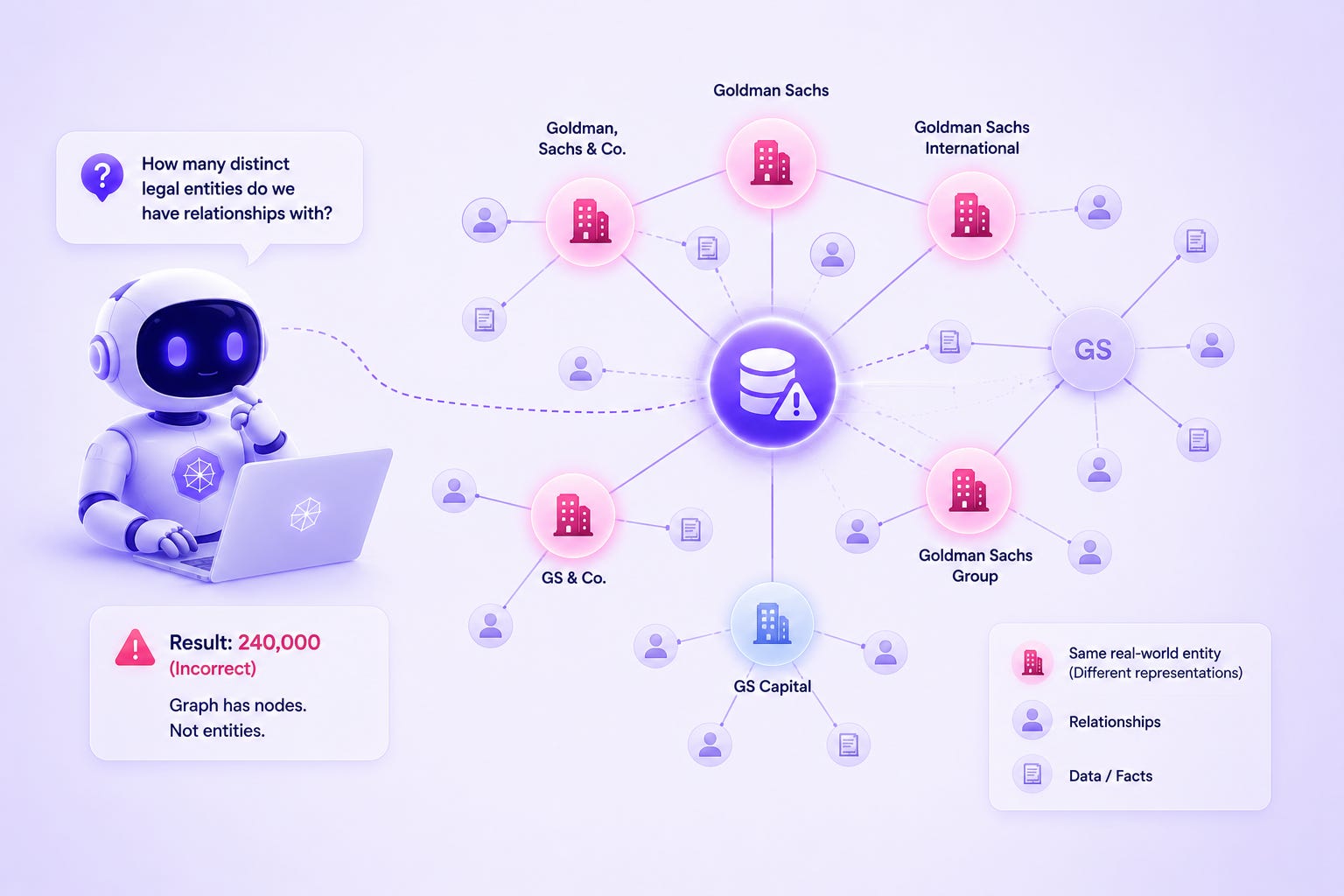
Then they ran a query asking how many distinct legal entities they had relationships with.
The graph said 240,000. Their compliance team knew from experience the real number was closer to 140,000. The graph had created a node for every record, not every entity. “Goldman Sachs,” “Goldman, Sachs & Co.,” “Goldman Sachs International,” and “GS” were four separate nodes — unlinked, unresolved, floating as if they had nothing to do with each other.
Nine months. Significant infrastructure investment. And the output was fundamentally untrustworthy.
This is the quiet failure mode of most enterprise knowledge graph projects. Not in the technology, but in what teams assumed away before they started.
What a Knowledge Graph Is Actually Promising You
Traditional SQL gives you rows. A knowledge graph gives you the network — customers connected to orders, legal entities connected to subsidiaries and counterparties, relationships that flat tables can’t express.
The power is real. But it comes with a catch that most teams discover too late.
Juan Sequeda, Principal Researcher at ServiceNow and co-author with Ora Lassila of Designing and Building Enterprise Knowledge Graphs, frames the core problem precisely: the goal is to reason across connected entities — but that reasoning only holds if you can trust that each node actually represents what it claims to represent.
Relationships between nodes are only meaningful if you know which node is actually which entity. If “Goldman Sachs” and “GS Capital” are two separate nodes when they should be one, every relationship attached to either is incomplete. Your compliance query returns partial results. Your fraud model misses a connection. Your customer 360 view has invisible holes.
As Ora Lassila — co-author of the original RDF specification and the Semantic Web paper with Tim Berners-Lee — has observed: enterprise data is messy at best. Messiness that gets structured into a graph doesn’t go away. It becomes structurally embedded.
The Specific Problem: Synonym Nodes
In graph terminology, the failure mode has a name: synonym nodes. Two nodes that represent the same real-world entity, appearing as separate entries because source data spelled the name differently, abbreviated differently, or came from a system that had no way to know the other record existed.
The problem is structural, not accidental. Most enterprise knowledge graph construction involves pulling data from multiple sources — CRM, ERP, compliance filings, third-party data providers. These systems were never built to agree on identity. Each assigned its own identifiers, its own formats, its own rules for what counts as a “company” or a “person.” When you combine those sources into a graph, you inherit every one of those disagreements simultaneously.
Variations don’t have to be dramatic to cause real damage. “Robert Smith,” “Bob R. Smith,” and “Robert Smith Jr.” might all be the same person — or they might not. The graph cannot tell. And when you’re integrating a new data source, you face the same question for every incoming record: does this refer to a node you already have, or is it a genuinely new entity? Without entity resolution, you can’t answer that. You just create new nodes.
A March 2026 piece in Medium on knowledge graph normalization described the failure mode directly: if variations are added to a graph without careful handling, the result is a cluttered structure with duplicate nodes, broken identities, and relationships that appear more complex than the underlying reality. This isn’t a fringe problem — it’s the default outcome when identity is treated as something to clean up later.
The scale this reaches in production is significant. Research documented by Graph Praxis found that Children’s Medical Center Dallas discovered 22% of their patient records were duplicates before implementing proper entity resolution — a figure that dropped to 0.14% afterward. In healthcare, that’s the difference between a care team seeing a complete patient history and seeing a fragment. In financial services, it’s the difference between detecting a counterparty exposure and missing it entirely.
Why This Gets Worse Under AI
This problem is old. What’s changed is the cost of ignoring it.
In a traditional BI workflow, an analyst queries the graph, notices something looks off, and flags it. Human attention catches the error before it becomes a decision. The feedback loop is slow but it exists.
In an agentic AI workflow, that loop is broken.
When an AI agent queries your knowledge graph — to answer a question, execute a task, or route a process — it trusts the graph. It takes the retrieved context as ground truth. It doesn’t pause to notice that there are six nodes for one customer, or that two supplier entries that look different are actually the same company. It acts on what it finds.
Research published in 2025 on denoising knowledge graphs for retrieval-augmented generation put numbers to this. The paper — from researchers at Nanyang Technological University, Nanjing University, and Mila — studied what happens when LLMs construct knowledge graphs automatically, as most GraphRAG implementations do. The finding is uncomfortable: LLMs consistently produce duplicate entities because they struggle to maintain consistency across long contexts. The entity “LLMs” might appear alongside “LLM,” “Large Language Models,” and “llms” — all as separate nodes, none linked. The paper found that simply applying entity resolution to remove these redundant nodes — reducing graph size by around 40% — consistently improved question-answering performance across all four GraphRAG variants tested. Less graph, better answers, because the graph that remained was actually trustworthy.
The implication is significant. The failure mode isn’t just in enterprise data pipelines assembled over years from messy source systems. It shows up in graphs that were constructed minutes ago by an LLM. The redundancy is structural to how language models generate graphs, not a legacy data problem you can engineer around. Entity resolution isn’t a preprocessing step for dirty old data — it’s a required component of any production GraphRAG pipeline.
The GraphRAG pattern — using knowledge graphs to ground LLM-based reasoning and reduce hallucination — is one of the most promising architectural approaches in enterprise AI right now. But the value of that pattern depends entirely on reasoning across correctly identified entities. If the nodes aren’t resolved, GraphRAG doesn’t reduce hallucination. It structures it.
What Entity Resolution Is Actually Doing
Entity resolution is the process of determining which records across a dataset — or across datasets — refer to the same real-world entity.
It sounds like deduplication, but it’s more than that. Deduplication removes exact copies. Entity resolution handles the fuzzy cases: variations in spelling, abbreviations, transpositions, name changes over time, intentional obfuscation. It combines probabilistic matching with learned models and, critically, continuous feedback that improves accuracy as new data arrives and edge cases are resolved.
For knowledge graph construction, entity resolution serves two distinct roles.
The first is deduplication within the graph: ensuring the node for a given entity appears once, with all relevant attributes consolidated, rather than scattered across variants. The second is linking across sources during ingestion: when a new data source arrives, entity resolution is what allows you to match incoming records to existing nodes rather than creating new ones for every record. It is the mechanism that makes multi-source integration coherent rather than merely cumulative.
The hardest part of building a knowledge graph isn’t the graph technology itself — it’s the data integration problem underneath. Getting multiple sources to agree on what an entity is, and which records refer to it, is the work that makes everything else possible. Entity resolution is where that agreement is actually enforced.
Academic research on this has been building for decades. A foundational paper from Jay Pujara at USC established that the collective relationships in a knowledge graph are themselves a key input to improving entity resolution — the graph structure helps resolve ambiguous records by triangulating on shared connections. Identity and graph quality improve each other iteratively, which is why treating entity resolution as a one-time preprocessing step misses the point.
What This Looks Like in Practice
Take a financial crimes use case — one of the most common production applications of knowledge graphs. You’re ingesting beneficial ownership data, sanctions lists, transaction records, and corporate registry filings. Each source has its own identifier for legal entities. The same holding company appears under slightly different names in each.
Without entity resolution, your graph has hundreds of thousands of nodes, many representing the same entity. A query looking for connections between a transaction counterparty and a sanctioned entity returns nothing — not because the connection doesn’t exist, but because the two nodes representing the same company were never linked.
The Knowledge Graph Conference 2024 featured sessions on exactly this pattern: compliance and financial crime use cases where the graph produced structurally accurate output, but missed the relationships that mattered most because entity resolution had not been done. The graph knew everything about each record. It knew nothing about the entities those records actually referred to.
The same principle applies in retail (supplier networks and customer identity across channels), in healthcare (patient identity across care settings and systems), and in any enterprise where AI agents are making operational decisions against data assembled from multiple source systems that never agreed on identity in the first place.
The Timing Problem
One more thing that makes this hard in practice: entity resolution isn’t a one-time job.
Data arrives continuously. New sources get added. Entities change — companies get acquired, people change names, addresses update. An entity resolution layer that runs once at graph construction time will degrade as new data accumulates. New records land without being matched to existing nodes. The graph grows stale in ways that are invisible until they cause a problem.
Production-grade entity resolution needs to be incremental: processing new records as they arrive, matching them against the existing entity model, updating the graph continuously rather than in batch. This is a substantially harder engineering problem than a one-time deduplication pass. It requires blocking strategies that make pairwise comparison feasible at scale, scoring models that learn from feedback, and audit trails that let you trace why two records were or weren’t resolved together.
Lassila’s observation about enterprise data messiness points to why this is so persistent: the root cause isn’t bad data entry — it’s that the systems generating the data were never designed to coordinate on identity. Every new source integration re-opens the problem. The only durable answer is infrastructure that handles it continuously, not a cleanup pass that eventually becomes stale.
The teams I work with that have gotten this right share one characteristic: they thought about identity before they thought about the graph. They didn’t build the graph and then ask how to clean it up. They solved the identity layer first, and let that become the foundation for everything they wanted to build.
The Right Order of Operations
If you’re planning a knowledge graph project — for GraphRAG, compliance analytics, customer intelligence, or supply chain visibility — the sequence matters more than the tooling.
Build identity first. Establish how your organization will recognize when two records refer to the same entity, across all the sources you plan to ingest. Build the infrastructure to run that matching continuously as new data arrives. Make sure the output of that process — a canonical, deduplicated, linked set of entities — is what flows into your graph.
Then build the graph on top of that foundation.
The entity resolution layer isn’t the glamorous part of this work. Knowledge graph visualization is compelling. The identity pipeline underneath it is infrastructure. But it’s the infrastructure that determines whether the graph reflects the world accurately — or just reflects your data’s history of accumulated confusion.
The goal of a knowledge graph is to reliably create knowledge from data. The word “reliably” is doing a lot of work in that sentence. Reliable knowledge requires resolved entities. There is no shortcut around it.
The teams that get this right will build AI systems that can actually be trusted to act. The teams that skip it will spend a long time wondering why their graph-powered AI keeps producing wrong answers — not because the model is bad, but because the ground truth it was given was never true to begin with.
What’s your experience building knowledge graphs in production? I’d love to hear where identity came up — and whether it was planned for, or discovered the hard way.
This is spot on, especially as agents setup by different engineers/departments/vendors manipulate data within a single org.
Our GTM agent did exactly this in its 2nd run, and we ended up running the wrong workflow on a lead with so much potential. We learned the hard way, and now resolve identity by domain lookup into typed ExternalID nodes before any write lands on the graph (we leverage our own product, Omnigraph, to govern agent writes back to the graph - https://github.com/ModernRelay/omnigraph).
Fixing these human-agent relationship issues will be key to compound knowledge across companies of all sizes, exciting times to be in this space!